圖靈測試2.0 如何判斷AI到底能干什么不能干什么

原標題:圖靈測試2.0 如何判斷AI到底能干什么不能干什么
圖靈測試本身是一個定性的、概念性的測試,理論上隨便哪個程序都可以通過縮窄測試范圍、限定測試集然后通過所謂的圖靈測試。
換成產品視角,情況則有所不同,這時候能否通過圖靈測試就會限定在產品的邊界以內,并且拳拳到肉,一旦不靈,AI驅動的產品就不成立了。本次測試就是抽取了真實產品的部分場景進行方便理解的再包裝,目的主要用于說明圖靈測試2.0這概念。
考慮潛在的誤讀,預先做如下聲明:
1.本測試不權威也不全面,但可復現,過程數據有留存。可復現是指按照步驟每個人都可以測試。
2.本測試不代表各個模型優劣,只代表和設定場景的匹配度。
3.本測試選擇模型有主觀性,在用的起和好用上做了權衡。
角色中心式計算與圖靈測試2.0
角色中心式計算是相對功能中心式計算說的。
到現在為止差不多所有我們用的APP是以功能來劃分的,職能相對單一,比如IM、搜索、外賣、打車等等。
一個角色職責的完成往往需要組合很多的功能,比如那怕一個招聘的角色它背后都必須組合十幾個工具(從IM到招聘APP等)才能完成招聘某個人的工作。
現在AI可以承擔這個居中調度的角色,所以應用的下一步必然是角色中心式計算。
而角色中心式計算是否成立,核心則在于AI的智商程度是否能夠處理角色邊界內的一切事情,比如招聘的時候要能判斷當前的JD的描述是否匹配需求方的需求也要判斷一個候選人是否初步匹配對應的招聘需求等。
如果角色的每一個這種關鍵步驟的都可以用AI來完成,那對這個角色而言就不單通過對話無法區分出這是真人還是AI,從現實的反饋也無法區分。
這就算通過了圖靈測試2.0。
這點之前展開比較多,這里不過多重復了。
在過去的文章里一直缺一個往下一步,怎么設計和實現圖靈測試2.0的例子,這篇文章重點在這里。
我們抽取一個真實場景的核心步驟,從易懂的角度包裝成一個極簡的例子,來說明圖靈測試2.0的概念怎么分解,和一個具體的角色怎么融合。
參見:
圖靈測試2.0的示例
假如我們打造這么一個簡單角色。
它是你的代理,可以幫助你按照你的設定在特定UGC平臺上發布你生成的內容。(OpenAI發布會上Greg Brockman演示過類似的例子)
我們略去大量細節來描述這個角色。
這樣一來這個角色就有4個關鍵內涵:
1.完成你對自己做的人設。
2.針對特定話題或者問題生成內容。
3.確保內容的質量。
4.發布等執行步驟。
第四步的發布等是傳統的RPA等技術,其實并不關鍵,后面就都略過了。
在這三個關鍵步驟里面,除了內容生成,還需要AI做的判斷是:
1.生成的內容是不是真的匹配對應的話題或者問題?(內容生成是一次性的,在多個平臺發布是多次性的,所以要經常做匹配的判斷)
2.內容的基礎質量到底怎么樣?
這兩項工作別看簡單,但在沒有AI大模型前還真的很難做好。在過去你就沒辦法針對特定問題、話題實時生成內容,也很難實時大批量的判斷匹配度。
有點像無機物到單細胞生物。
為了縮減文章篇幅,我們進一步降低目標。
完成第一項工作就變成生成一個內容的概要,然后大模型判斷內容概要和問題的匹配度。這里其實可以直接用模型,也可以用Embedding算法。
兩者各有利弊,但這里只關注用模型的判斷結果。
這步驟做完之后,比如你生成的內容是:青玉案元夕相關,那就可以匹配到古詩詞的標簽或者特定問題下面。
都測試完了之后,還需要用人來標注下最終測試結果,這樣就提供個絕對的尺度,知道AI大模型算法能進行到什么程度了。
第二項的評測簡化成使用BLEU算法來評測生成內容的相似度。
這是避免內容生成的重復。
為什么做這個呢?因為最終不希望反復發表一樣的內容。即使輸入相對一致,比如人設、話題等有相似性,也不希望內容一致。
至于是不是內容生成的足夠優美,就先不管了,那十分麻煩。
為了完成這個測試,需要一些真實數據,這可以手動編輯或者抓取。這部分和具體你輻射的領域有關系,文藝青年、斜杠青年等需要的數據不怎么一樣。但這和RPA一樣是個傳統的活,大部分程序員都會做。這里為了避免不必要的麻煩,數據先不公開了。
感興趣的人可以聯系cathywangyue進讀者群再部分討論吧。
完成了上面的工作,其實就完成了從一個角色到圖靈2.0測試集的基礎映射:關鍵是要分解角色內涵,為關鍵判斷建立測試集。
測試結果
在準備的1000條測試數據上,第一項測試最終結果是下面這樣:
這里面檢出率是指在1000條測試項目里,有多少模型判斷為匹配的,準確率是指在認為匹配的項目里面和人的標注比,準確率什么樣。
這個測試結果最終怎么用會和你的傾向性相關,顯然的數量優先和質量優先結果是不一樣的。
結果里面最有意思的點是:至少在這一個判斷項上,AI還不如人。所以如果判斷項比較多,整體精度的控制會是很有挑戰的問題。
然后我們測試的是內容生成部分的質量,這部分我們不測文辭是否優美這些,就測生成內容的最簡單的BLEU值,其中參數都用缺省參數,temperature這些就不改了。如果做的很細,這部分可以反復試多組值。但我們是為了說明圖靈測試2.0概念,就不做這部分了。
最終測試結果中得分前三的是:
全部模型的測試結果是:
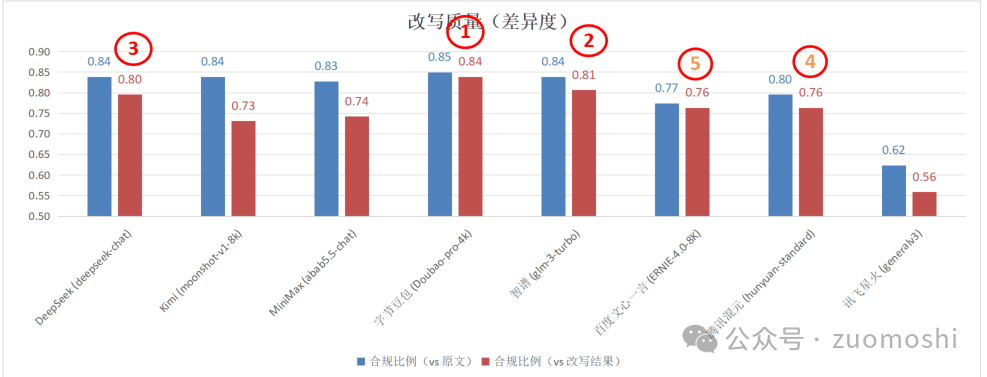
這里面和原文對比是指創作內容和原始種子做比較,然后統計BLEU值小于0.75的比例,0.85就意味著85%的內容差異度大于0.75。(原文可以看成是內容的種子,基于原文和提示詞生成對應內容。)
和改寫結果比是指,同樣的方法會生成3次內容,然后看BLEU值,把小于0.75的除以3就是上面的結果。當然提示詞中會包含加大差異度的部分。
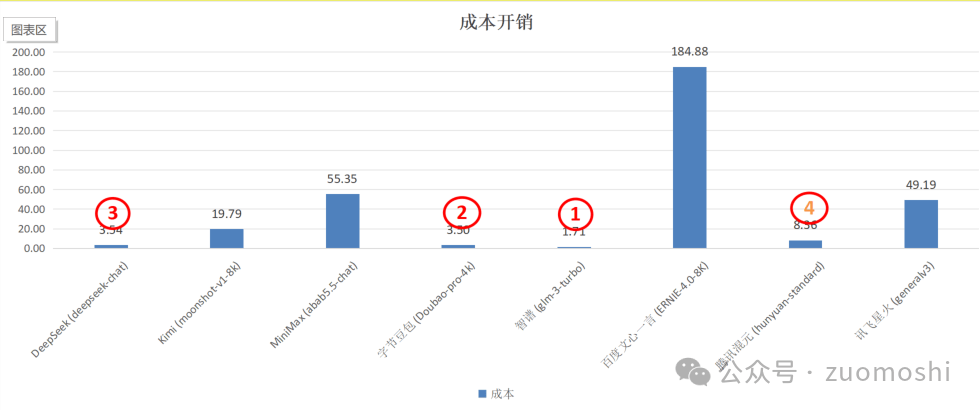
內容生成會比較耗費token,所以同步要記錄下token數目和費用。最終出了個價格離譜的,說明模型初選的時候選錯了。
例子的意義
當這種測試可以通過,那就意味著最終從技術視角看,對應的角色可以通過圖靈測試2.0。如果精度達不到一定程度,那你設定的角色在當前AI的智商下就不成立。不管多酷炫、別人多么吹捧但對解決你設想的問題都沒意義。
其次是要理解,任何一個角色的成立要涵蓋對應角色的N多方面。
用AI來做亮眼的Demo,和用AI做真正能用的產品,兩者的難度不在一個數量級,雖然看著都是差不多的東西。這就是一般鏡頭和哈勃望遠鏡的鏡頭的區別。
這種測試結果也可以標識從產品角度看到的AI的真實進展。往往和某些媒體上來的認知有很大偏差。
落地時里面的項目和復雜度當然需要進一步增加。
但如果真想用AI,那現在開始就需要建立你自己的測試集,并且在模型還不穩定的時候定期測試。
假設這個測試集里面的數據采樣足夠豐富,再加上一個對接到各個大模型的測試框架,那在你的領域你會比任何人都權威,不用聽任何人的。
這就是之前說的一手體驗。
這里面對一般人有點挑戰的倒不是提示詞怎么寫,這部分資料比較多,反復測試可以找到解決方案,最不濟還可以問AI。
麻煩一點的是怎么組合各種算法。
不是所有的時候都只用大模型一種算法就行的。
這部分只能陸續探討,沒有唯一解決方法。
限制
上述方法現在可以用于支持一些比較簡單的角色。
但因為角色自身的行為模式還是基于規則,只能在限定的流程框架里面完成任務。
如果角色過于復雜,可能還需要進一步的AI進步,暫時可以先別整。
但這已經能夠打造一些和過去不一樣的應用了。
小結
最終再總結下圖靈測試2.0的全過程:先定義你認為有商業價值的角色,然后依據角色挖掘它的內涵,具體成相應的圖靈測試2.0的測試集,然后就反復測試各種模型。如果能通過,那從技術角度角色也成立,產品可以啟動。否則就得等等。回到現場的一手體驗,是AI產品的最最關鍵的起點。
?????投稿郵箱:jiujiukejiwang@163.com ??詳情訪問99科技網:http://www.hacbq.cn
 OpenAI測試GPT-4o圖像生成水印,ChatGPT Plus用戶可免
OpenAI測試GPT-4o圖像生成水印,ChatGPT Plus用戶可免
原標題:OpenAI測試GPT-4o圖像生成水印,ChatGPT Plus用戶可免水印保存? 近期,科
互聯網+2025-04-07



 谷歌 YouTube 短視頻 Shorts 正測試加廣告
谷歌 YouTube 短視頻 Shorts 正測試加廣告
原標題:谷歌 YouTube 短視頻 Shorts 正測試加廣告 據 MSPoweruser 報道,谷歌 YouTub
互聯網+2022-04-29






 推薦資訊
推薦資訊






